
本站提供的文件下载服务面向全球用户,尽管我们会时刻监控服务的可用情况,难免还是会出现某些节点欠费、流量耗尽等异常情况,导致用户无法顺利下载文件。如果您在本站下载期间正好碰到类似异常情况,希望您能提供网址响应信息帮助我们尽早排查问题所在。响应信息对许多网友比较陌生,本文简要解释网址响应信息的含义,并给出获取方法。
网址响应信息
简单来说,网址响应信息就是:当我们请求一个网址时,服务器回给我们的最基本信息,例如:请求是否成功,文件有多大,文件什么类型,诸如此类的信息。
现实中网址响应信息基本上都由浏览器帮忙处理,所以浏览器也被称为“用户代理”(User Agent)。浏览器是方便好用的工具,但是遇到底层问题时界面上显示的信息已经经过过滤,不能很好的展示问题的真实原因。
因此为了快速排查问题,我们需要网址的响应信息。下文介绍获取网址相信信息的方法。
使用curl获取响应信息
curl 是常用的网络命令行工具,功能非常强大。如果你使用Mac、Linux、WSL或Cygwin/MYSY2等环境,curl 命令基本上已经内置。使用 curl 获取网址响应信息的命令为: curl -sI 网址。例如获取本站首页信息,将有如下输出:
$ curl -sI https://netfiles.pw HTTP/2 200 server: nginx date: Sat, 29 Feb 2020 13:29:45 GMT content-type: text/html; charset=UTF-8 vary: Accept-Encoding link: <https://netfiles.pw/wp-json/>; rel="https://api.w.org/" link: <https://netfiles.pw/>; rel=shortlink strict-transport-security: max-age=63072000; preload x-frame-options: SAMEORIGIN x-content-type-options: nosniff x-xss-protection: 1; mode=block
“HTTP/2″开头到结束的信息便是本站首页的响应信息,虽然你可能看不懂,但获取是不是很方便呢?如果遇到问题,用 curl 命令获取一下网址的信息,然后提交给我们,便是帮了我们的大忙。
使用浏览器获取响应信息
对于Windows用户,建议的做法是使用浏览器获取网址信息信息,而不是安装Windows版的 curl 命令再获取。浏览器获取响应信息的方法适用于任何装有浏览器的平台,本文以chrome浏览器为例说明获取方法,也适用于火狐、搜狗、360等浏览器。
操作步骤如下:
1. 打开chrome浏览器,新建一个标签页;
2. 按F12唤出开发工具,点击”Network”标签页:

chrome开发者工具
3. 在网址栏输入或粘贴网址,例如输入本站首页“https://netfiles.pw”,然后按回车键。下方的工具栏可能会出现很多行,找到第一行:
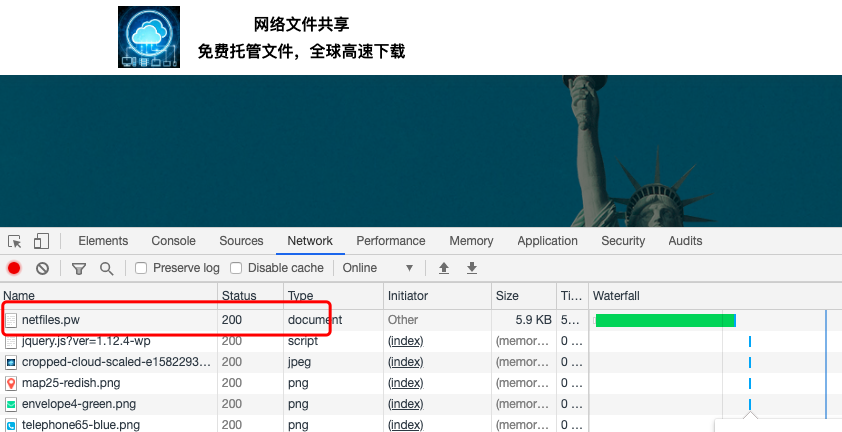
chrome网络请求记录
4. 点击第一行,右侧出现这一行的详细信息。点击Headers标签,找到“Response Headers”,这就是完整的网址响应信息,和 curl 命令拿到的基本一致:
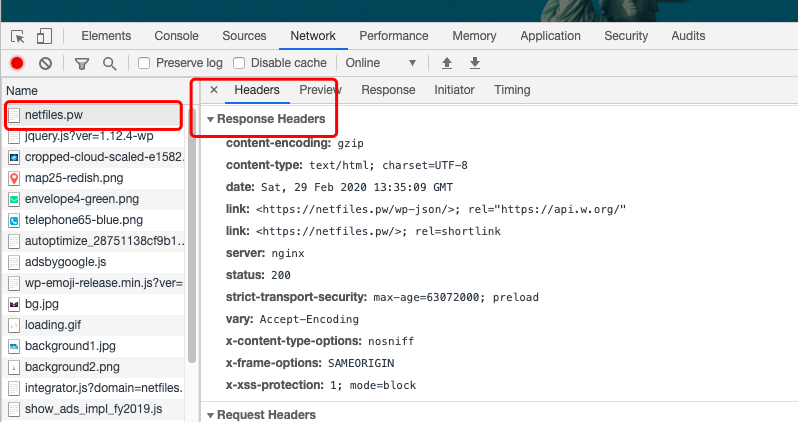
chrome查看响应信息
5. 拿到了响应信息,复制后和两外两条信息一起提交给我们吧!
如有疑问,欢迎在页面留言。