
文章原文:https://binbinmeng.wordpress.com/2018/10/19/nvidia-gpu%E4%B8%AD%E7%9A%84unified-memory/
由于最近在公司内部做一场关于gpu unified memory的的技术分享,本人最近对该技术点进行了技术调研,现在作一篇技术总结。本总结分为四大部份:
- <1> Unified Memory在各个GPU架构中的发展脉络
- <2>Unified Memory的最新特性
- <3>Unified Memory性能的调优策略
- <4>Unified Memoryd的应用案例
Unified Memory在各个GPU架构中的发展脉络
说到Unified Memory,它其实只是一种在Pascal架构/Volta架构/Turing架构中存在的一种新型内存编程模型,即它不是一种物理上新型的gpu显存设计。
UnPinned Memory vs Pinned Memory
说到这里,我们不得不回顾一下GPU的内存管理方式。GPU显存从管理方式上来看分为两大类:pinned memory[又称page-locked memory] | unpinned memory[又称pageable memory].
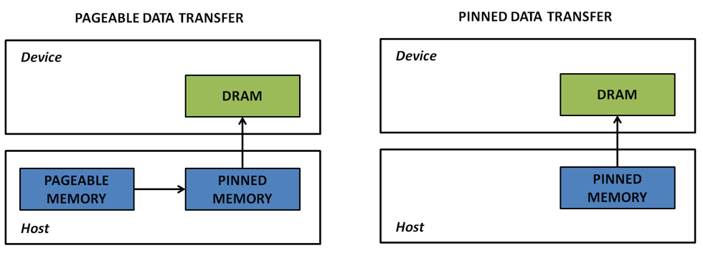
从两种内存的传输方式对比图可以看出:pinned memory(又称锁页内存,不能被OS置换的内存,且固定在主机内存的一块区域)中的数据传输到gpu显存只需要传输一次即可。unpinned memory就是我们所说的常规主机内存,可以被OS交换的内存。如果申请的是这样的内存区域,当传输数据到设备内存时,隐式地会发生两次传输。首先,OS会开辟一开临时的锁业内存作为中转站,数据先传给该临时的锁页内存,然后再由锁页内存传给设备内存。理论上,可以得出以下结论:锁页内存的传输效率高于可交换内存。
GPU知道页锁定内存的物理地址,可以通过“直接内存访问(Direct Memory Access,DMA)”技术直接在主机和GPU之间复制数据,速率更快。
实际上两者的效率对比,可以参考如下图:(测试平台为K20)

从gpu编程角度来看,两种内存的操作,有如下不同。

Zero-Copy Memory
这里说下一种特殊的Pinned Memory:zero-copy memory,它是在cuda2.2中开始被引入。从名字便可以看出这中内存的特点:zero copy, 即无需进行数据的拷贝。具体的过程可以理解为:当OS分配出锁页内存后,并不需要显示的进行数据传输操作。直观上来看,GPU内核可以直接访问这片锁页内存。比如,申请如下一块锁页内存:
cudaHostAlloc((void **)&pinnedHostPtr, THREADS * sizeof(double), cudaHostAllocMapped);
其中指向锁页内存的pinnedHostPtr 只能从主机端访问锁页内存。如果kernel想操作这片区域,必须利用如下操作,进行内存映射(mapping):
double* device_Ptr;
cudaHostGetDevicePointer(&device_Ptr, pinnedHostPtr, 0);
映射完之后,gpu kernel便可以操作了。
testPinnedMemory<<< numBlocks, threadsPerBlock>>>(device_Ptr);
我们发现了什么呢?没有显示的数据传输(cudamemcpy),是不是瞬间觉得简便多了。对于习惯使用了可交换内存,然后显式传输数据的方式,这样的基于zero-copy memory的方式,其实效率更高,使用更加便捷。
Default Pinned Memory vs Zero-Copy Memory
常规锁页内存的使用场景:
①Transfer data not too often
②Long time on IO than computation
零拷贝内存的使用场景:
①Intergrated gpu card (TK1,TX1/TX2)
②Long time on computation than IO
③Asynchronous tasks
④Gpu memory capacity is limited
Unified virtual addressing (UVA)
UVA技术是在cuda4中开始引入的。在它出现之前,CPU内存和GPU内存分别使用各自的地址空间,彼此数据传输时需要地址转换。而UVA就是解决这个问题:支持UVA的情况下(支持的系统会自动启动UVA),CPU内存与GPU内存共用一套地址空间。示意图如下:

同一地址空间访问技术其为 一个指针管理两份不同的memory 提供了基础。
从编程角度来看,UVA带来的好处是,开发者再也不需要显示的指定数据的拷贝方向了,一个cudaMemcpyDefault即可搞定。对于CPU端的可分页非锁定内存和GPU端的内存,CUDA可以自动推断出来该内存指针位于那个设备上面。在UVA模式下,对于CPU端分页锁定内存,默认被映射和可分享的。

peer-to-peer
当UVA不支持时,在多卡环境下编程时,我们会碰到GPU与GPU之间的数据拷贝,使用的函数为:
- __host__ cudaError_t cudaMemcpyPeer ( void* dst, int dstDevice, const void* src, int srcDevice, size_t count )
- __host__ cudaError_t cudaMemcpyPeerAsync ( void* dst, int dstDevice, const void* src, int srcDevice, size_t count, cudaStream_t stream = 0 )
当系统支持UVA时,我们就不必指定两个设备了,CUDA可以通过指针推断出来源于那个设备。因此,只需简化使用cudaMemcpy()函数就可以了。
__host__ cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count, cudaMemcpyKind kind )
无论UVA系统支持与否,都有两个特点:
- 非点对点映射,只能称之为点对点内存拷贝
- 之前的这两种GPU之间数据拷贝其实是以CPU内存为媒介进行拷贝的,当我们使用nvvp软件查看GPU之间数据传输的timeline时,我们就发现整个拷贝包含两个步骤:
- SrcDevice to CPU (D2H)
- CPU to dstDevice (H2D)
其实有一种更快的点对点寻址方式,peer-to-peer拷贝。这个特性不是默认打开的.
通常我们需要这两步骤:
第一步,判断设备A是否可以通过P2P方式访问设备B:
__host__ cudaError_t cudaDeviceCanAccessPeer ( int* canAccessPeer, int device, int peerDevice )
第二步,如果可以,那么将P2P方式打开:
__host__ cudaError_t cudaDeviceEnablePeerAccess ( int peerDevice, unsigned int flags )
注意,这两步只是满足了设备A对设备B内存P2P访问,而设备B却无法对设备A P2P访问,因为这个是非对称的,仍需要使设备B对设备A做同样的操作。
当我们使用nvvp软件查看GPU之间数据传输的timeline时,我们就会发现,这是GPU之间的拷贝只包含了一个P2P的过程了。
GPUDirect
什么是GPUDirect? GPUDirect是GPU与其他设备通信的技术概括,包含了一系列的技术特性。
- 2010年,GPU可以与处于PCIE总线上的设备通过共享pinned memory来进行通信,取消了一次CPU内存中分页锁定内存向另外一段内存的拷贝过程。

2. 2011年,增加了P2P特性,也就是我们刚才讲的GPU之间P2P的通信。因为取消了CPU内存的“媒介”功能,使得速度提升。

3. 2013年,引入了RDMA的特性,这个特性将使得GPU与第三方存储设备之间可以直接数据通信,同样取消了CPU内存的“媒介”功能。

Geforce GPU 不支持 P2P 传输、不支持 GPUDirect、不支持 UVA定址功能.
Unified Memory
前边做了半天的背景铺垫,接下来再进行unified memory的介绍,可能会更加有利于理解。
unified memory是从CUDA 6.0开始引入的,它带来的最直接的好处就是开发者不需要再用两套指针分别管理主机内存和设备内存,仅仅一个指针即可。(这里回忆一下零拷贝内存,它也是简化了指针的管理,但是它还是需要做一次内存映射的)

和之前的编程方式比区别如下:(仅仅维护一个指针,CPU/GPU都可以直接操作!)

Unified memory的发展前后也是经历了多代GPU架构。
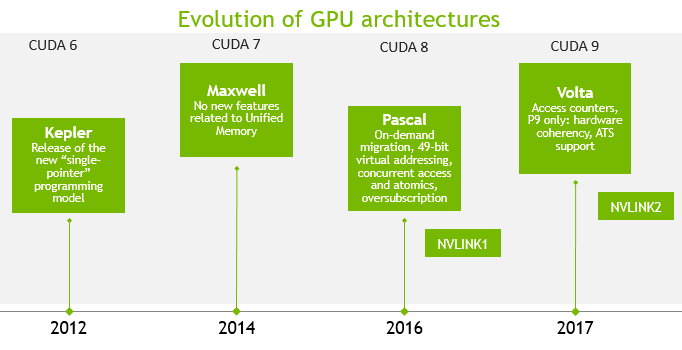
看过这幅图,其实可以看出在Pascal架构和Volta架构上unified memory的特性才算真正趋于成熟,所以接下来的内容才是本文的重点。
Pre-Pascal 架构上的 Unified Memory
以一个例子来说明在Kepaler/Maxwell架构上的UM的工作原理.

第一句代码:申请GPU显存,此时页面会在GPU上创建。
第二句代码:CPU访问内存,数据将会migrate 到CPU中。
第三句代码:GPU内核访问,数据会migrate到GPU中,并且只有在内核启动时会migrate一次。
特点:
- 由于页面会在内存被访问前就创建了,因此不能够超额分配(oversubscribe)。
- 由于只有在GPU内核访问时页面才会被迁移到GPU,就会存在一次性迁移问题【这就意味只在每一次内核启动前都将花费大量时间migration上】,因此不存在按需迁移(migrate on-demand)。【本质上是由于pre-pascal unified memory不能支持页错误处理机制】
Pascal/Valta 架构上的 Unified Memory
ON-DEMAND PAGE MIGRATION
硬件上引入PAGE MIGRATION ENGINE,支持Virtual Memory Demand Paging,其实就是gpu硬件层面支持页面错误处理机制【handle thousands of simultaneous page faults】。因为没有该特性的话,应用要提前将数据都加载到GPU显存中,这样势必会带来很大的开销。
再以一个例子来说明:

第一句代码:申请GPU显存,此时在GPU上不会创建页面。
第二句代码:CPU访问内存,出现也错误,数据将会在CPU中分配。
第三句代码:GPU内核访问,出现页错误,数据会migrate到GPU中。
特点:
- 如果系统不支持UVA,则系统会向CPU发送一个中断。
- Unified Memory driver会决定会映射还是迁移数据。
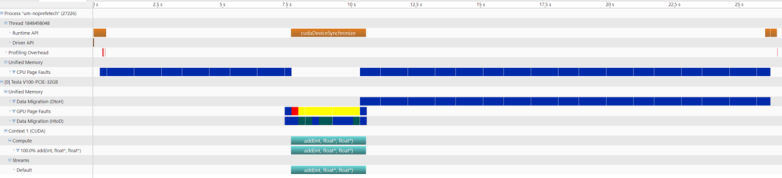
实际使用怎么样呢?

结果很让我们失望,基于P100的结果竟然比K80还慢。What’s up ???
常规的接口:

用cudaMemPrefetchAsync()优化一下:
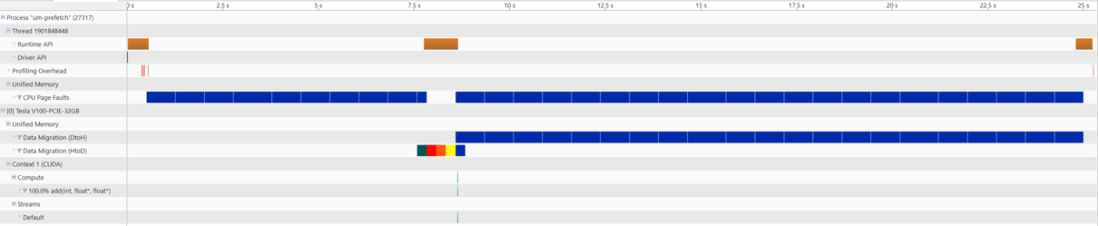

没有了GPU 页面错误的问题了。
最新的架构上的UM的新特性有如下四大方面:(前文已经介绍了第一个特性)

接下来重点介绍其他几个特性:
memory oversubscription
就是说利用cudaMallocManaged分配GPU显存的大小可以超过GPU物理上拥有的显存空间大小。就算分配超额也不会出现错误,其上限取决于OS系统内存大小。Kapler/Maxwell架构上,超额就会出错。
性能到底怎么样?来两个实验数据看看:
从实验可以看到:当超额分配的时候,GPU程序还是可以正常工作的,只是超额后GPU程序的性能会有所下降。
concurrent CPU/GPU access
还是以例子来说明

由于GPU kernel的执行和CPU执行是异步的,这就导致:如果没有synchronize,即没有等kernel执行完,那么data[]数据会同时被GPU和CPU 访问,具体data[1]被GPU访问,data[0]被CPU访问。这就是所谓的CPU/GPU并发访问的问题。
这个现象如果在pacal之前的架构的GPU 上面会出现“段错误”,而在pascal架构上,不会有问题。
Unified Memory性能的调优策略
- Unified Memory enables easy access to GPU development
- But some tuning might be needed for best performance
- It’s important to understand how on-demand page migration works.

策略一:Avoiding page faults by prefetching

策略二:Read duplication to allow high b/w access from multiple processors

策略三:Combining read duplication with prefetching
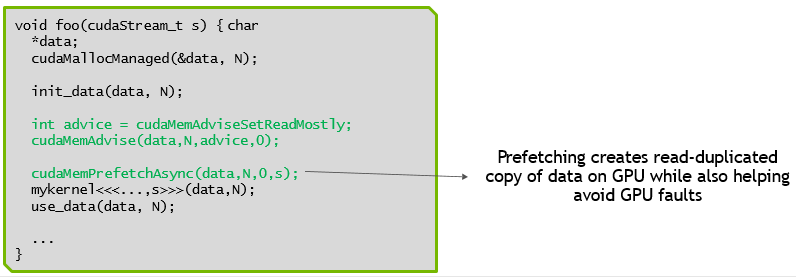
策略四:Setting preferred location to keep data local to most accessing processor

策略五:Avoiding faults by pre-mapping
