
redux、react-redux、redux-saga总结

前言
hello大家好,我是风不识途,最近一直在整理
redux系列文章,发现对于初学者不太友好,关系错综复杂,难倒是不太难,就是比较复杂(其实写比较少),所以这篇带你全面了解
redux、react-redux、redux-thunk还有redux-sage,immutable(多图预警),由于知识点比较多,建议先收藏(收藏等于学会了),对你有帮助的话就给个赞👍


认识纯函数
JavaScript纯函数
- 函数式编程中有一个概念叫纯函数,
JavaScript符合函数式编程的范式, 所以也有纯函数的概念 - 在
React中,纯函数的概念非常重要,在接下来我们学习的Redux中也非常重要,所以我们必须来回顾一下纯函数 - 纯函数的定义简单总结一下:
- 纯函数指的是, 每次给相同的参数, 一定返回相同的结果
- 函数在执行过程中, 不能产生副作用
- 纯函数(
Pure Function)的注意事项:- 在纯函数中不能使用随机数
- 不能使用当前的时间或日期, 因为结果是会变的
- 不能使用或者修改全局状态, 比如DOM,文件、数据库等等(因为如果全局状态改变了,它就会影响函数的结果)
- 纯函数中的参数不能变化,否则函数的结果就会改变
React中的纯函数
- 为什么纯函数在函数式编程中非常重要呢?
- 因为你可以安心的写和安心的用
- 你在写的时候保证了函数的纯度,实现自己的业务逻辑即可,不需要关心传入的内容或者函数体依赖了外部的变量
- 你在用的时候,你确定你的输入内容不会被任意篡改,并且自己确定的输入,一定会有确定的输出
- React非常灵活,但它也有一个严格的规则:
- 所有React组件都必须像”纯函数”一样保护它们的”props”不被更改
认识Redux
为什么需要redux
JavaScript开发的应用程序, 已经变得非常复杂了:JavaScript需要管理的状态越来越多, 越来越复杂了- 这些状态包括服务器返回的数据, 用户操作的数据等等, 也包括一些
UI的状态
- 管理不断变化的
state是非常困难的:- 状态之间相互存在依赖, 一个状态的变化会引起另一个状态的变化,
View页面也有可能会引起状态的变化 - 当程序复杂时,
state在什么时候, 因为什么原因发生了变化, 发生了怎样的变化, 会变得非常难以控制和追踪
- 状态之间相互存在依赖, 一个状态的变化会引起另一个状态的变化,

React的作用
React只是在视图层帮助我们解决了DOM的渲染过程, 但是state依然是留给我们自己来管理:- 无论是组件定义自己的
state,还是组件之间的通信通过props进行传递 - 也包括通过
Context进行数据之间的共享 React主要负责帮助我们管理视图,state如何维护最终还是我们自己来决定
- 无论是组件定义自己的
Redux就是一个帮助我们管理State的容器:Redux是JavaScript的状态容器, 提供了可预测的状态管理
Redux除了和React一起使用之外, 它也可以和其他界面库一起来使用(比如Vue), 并且它非常小 (包括依赖在内,只有2kb)

Redux的核心理念-Store
Redux的核心理念非常简单- 比如我们有一个朋友列表需要管理:
- 如果我们没有定义统一的规范来操作这段数据,那么整个数据的变化就是无法跟踪的
- 比如页面的某处通过
products.push的方式增加了一条数据 - 比如另一个页面通过
products[0].age = 25修改了一条数据
- 整个应用程序错综复杂,当出现
bug时,很难跟踪到底哪里发生的变化

Redux的核心理念-action
Redux要求我们通过action来更新state:- 所有数据的变化, 必须通过
dispatch来派发action来更新 action是一个普通的JavaScript对象,用来描述这次更新的type和content
- 所有数据的变化, 必须通过
- 比如下面就是几个更新
friends的action:- 强制使用
action的好处是可以清晰的知道数据到底发生了什么样的变化,所有的数据变化都是可跟追踪、可预测的 - 当然,目前我们的
action是固定的对象,真实应用中,我们会通过函数来定义,返回一个action
- 强制使用

Redux的核心理念-reducer
- 但是如何将
state和action联系在一起呢? 答案就是reducerreducer是一个纯函数reducer做的事情就是将传入的state和action结合起来来生成一个新的state

Redux的三大原则
- 单一数据源
- 整个应用程序的
state被存储在一颗object tree中, 并且这个object tree只存储在一个store Redux并没有强制让我们不能创建多个Store,但是那样做并不利于数据的维护- 单一的数据源可以让整个应用程序的
state变得方便维护、追踪、修改
- 整个应用程序的
- State是只读的
- 唯一修改
state的方法一定是触发action, 不要试图在其它的地方通过任何的方式来修改state - 这样就确保了
View或网络请求都不能直接修改state,它们只能通过action来描述自己想要如何修改state - 这样可以保证所有的修改都被集中化处理,并且按照严格的顺序来执行,所以不需要担心
race condition(竟态)的问题
- 唯一修改
- 使用纯函数来执行修改
- 通过
reducer将旧state和action联系在一起, 并且返回一个新的state - 随着应用程序的复杂度增加,我们可以将
reducer拆分成多个小的reducers,分别操作不同state tree的一部分 - 但是所有的
reducer都应该是纯函数,不能产生任何的副作用
- 通过
Redux的基本使用
Redux中核心的API
redux的安装: yarn add redux
createStore可以用来创建store对象store.dispatch用来派发action,action会传递给storereducer接收action,reducer计算出新的状态并返回它 (store负责调用reducer)store.getState这个方法可以帮助获取store里边所有的数据内容store.subscribe方法可以让让我们订阅store的改变,只要store发生改变,store.subscribe这个函数接收的这个回调函数就会被执行

小结
- 创建
sotore, 决定 store 要保存什么状态 - 创建
action, 用户在程序中实现什么操作 - 创建
reducer, reducer 接收 action 并返回更新的状态
Redux的使用过程
- 创建一个对象, 作为我们要保存的状态
- 创建
Store来存储这个state- 创建
store时必须创建reducer - 我们可以通过
store.getState来获取当前的state
- 创建
- 通过
action来修改state- 通过
dispatch来派发action - 通常
action中都会有type属性,也可以携带其他的数据
- 通过
- 修改
reducer中的处理代码- 这里一定要记住,
reducer是一个纯函数,不能直接修改state - 后面会讲到直接修改
state带来的问题
- 这里一定要记住,
- 可以在派发
action之前,监听store的变化
import { createStore } from 'redux'
// 1.初始化state
const initState = { counter: 0 }
// 2.reducer纯函数 不能修改传递的state
function reducer(state = initState, action) {
switch (action.type) {
case 'INCREMENT':
return { ...state, counter: state.counter + 1 }
case 'ADD_COUNTER':
return { ...state, counter: state.counter + action.num }
default:
return state
}
}
// 3.store 参数放一个reducer
const store = createStore(reducer)
// 4.action
const action1 = { type: 'INCREMENT' }
const action2 = { type: 'ADD_COUNTER', num: 2 }
// 5.订阅store的修改
store.subscribe(() => {
console.log('state发生了改变: ', store.getState().counter)
})
// 6.派发action
store.dispatch(action1)
store.dispatch(action2)
Redux结构划分
- 如果我们将所有的逻辑代码写到一起, 那么当
redux变得复杂时代码就难以维护 - 对代码进行拆分, 将
store、reducer、action、constants拆分成一个个文件
<details>
<summary>拆分目录</summary>
</details>

Redux使用流程

Redux官方流程图

React-Redux的使用
redux融入react代码(案例)
redux融入react代码案例:Home组件:其中会展示当前的counter值,并且有一个+1和+5的按钮Profile组件:其中会展示当前的counter值,并且有一个-1和-5的按钮
- 核心代码主要是两个:
- 在
componentDidMount中订阅数据的变化,当数据发生变化时重新设置counter - 在发生点击事件时,调用
store的dispatch来派发对应的action
- 在

自定义connect函数
当我们多个组件使用
redux时, 重复的代码太多了, 比如: 订阅state取消订阅state或 派发action获取state将重复的代码进行封装, 将不同的
state和dispatch作为参数进行传递

// connect.js
import React, { PureComponent } from 'react'
import { StoreContext } from './context'
/**
* 1.调用该函数: 返回一个高阶组件
* 传递需要依赖 state 和 dispatch 来使用state或通过dispatch来改变state
*
* 2.调用高阶组件:
* 传递该组件需要依赖 store 的组件
*
* 3.主要作用:
* 将重复的代码抽取到高阶组件中,并将该组件依赖的 state 和 dispatch
* 通过调用mapStateToProps()或mapDispatchToProps()函数
* 并将该组件依赖的state和dispatch供该组件使用,其他使用store的组件不必依赖store
*
* 4.connect.js: 优化依赖
* 目的:但是上面的connect函数有一个很大的缺陷:依赖导入的 store
* 优化:正确的做法是我们提供一个Provider,Provider来自于我们
* Context,让用户将store传入到value中即可;
*/
export function connect(mapStateToProps, mapDispatchToProps) {
return function enhanceComponent(WrapperComponent) {
class EnhanceComponent extends PureComponent {
constructor(props, context) {
super(props, context)
// 组件依赖的state
this.state = {
storeState: mapStateToProps(context.getState()),
}
}
// 订阅数据发生变化,调用setState重新render
componentDidMount() {
this.unsubscribe = this.context.subscribe(() => {
this.setState({
centerStore: mapStateToProps(this.context.getState()),
})
})
}
// 组件被卸载取消订阅
componentWillUnmount() {
this.unsubscribe()
}
render() {
// 下面的WrapperComponent相当于 home 组件(就是你传递的组件)
// 你需要将该组件需要依赖的state和dispatch作为props进行传递
return (
<WrapperComponent
{...this.props}
{...mapStateToProps(this.context.getState())}
{...mapDispatchToProps(this.context.dispatch)}
/>
)
}
}
// 取出Provider提供的value
EnhanceComponent.contextType = StoreContext
return EnhanceComponent
}
}
// home.js
// 定义组件依赖的state和dispatch
const mapStateToProps = state => ({
counter: state.counter,
})
const mapDispatchToProps = dispatch => ({
increment() {
dispatch(increment())
},
addNumber(num) {
dispatch(addAction(num))
},
})
export default connect(mapStateToProps,mapDispatchToProps)(依赖redux的组件)react-redux使用
- 开始之前需要强调一下,
redux和react没有直接的关系,你完全可以在React, Angular, Ember, jQuery, or vanilla JavaScript中使用Redux - 尽管这样说,redux依然是和React或者Deku的库结合的更好,因为他们是通过state函数来描述界面的状态,Redux可以发射状态的更新,让他们作出相应。
- 虽然我们之前已经实现了
connect、Provider这些帮助我们完成连接redux、react的辅助工具,但是实际上redux官方帮助我们提供了react-redux的库,可以直接在项目中使用,并且实现的逻辑会更加的严谨和高效 - 安装
react-redux:yarn add react-redux
// 1.index.js
import { Provider } from 'react-redux'
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById('root')
)
// 2.home.js
import { connect } from 'react-redux'
// 定义需要依赖的state和dispatch (函数需要返回一个对象)
export default connect(mapStateToProps, mapDispatchToProps)(About)react-redux源码导读

Redux-Middleware中间件
组件中异步操作
- 在之前简单的案例中,
redux中保存的counter是一个本地定义的数据- 我们可以直接通过同步的操作来
dispatch action,state就会被立即更新。 - 但是真实开发中,
redux中保存的很多数据可能来自服务器,我们需要进行异步的请求,再将数据保存到redux中
- 我们可以直接通过同步的操作来
- 网络请求可以在
class组件的componentDidMount中发送,所以我们可以有这样的结构:

redux中异步操作
- 上面的代码有一个缺陷:
- 我们必须将网络请求的异步代码放到组件的生命周期中来完成
- 为什么将网络请求的异步代码放在
redux中进行管理?- 后期代码量的增加,如果把网络请求异步函数放在组件的生命周期里,这个生命周期函数会变得越来越复杂,组件就会变得越来越大
- 事实上,网络请求到的数据也属于状态管理的一部分,更好的一种方式应该是将其也交给
redux来管理

- 但是在
redux中如何可以进行异步的操作呢?- 使用中间件 (Middleware)
- 学习过
Express或Koa框架的童鞋对中间件的概念一定不陌生 - 在这类框架中,
Middleware可以帮助我们在请求和响应之间嵌入一些操作的代码,比如cookie解析、日志记录、文件压缩等操作
理解中间件(重点)
redux也引入了中间件 (Middleware) 的概念:- 这个<font color=’red’>中间件的目的是在
dispatch的action和最终达到的reducer之间,扩展一些自己的代码</font> - 比如日志记录、调用异步接口、添加代码调试功能等等
- 这个<font color=’red’>中间件的目的是在

redux-thunk是如何做到让我们可以发送异步的请求呢?- 默认情况下的
dispatch(action),action需要是一个JavaScript的对象 redux-thunk可以让dispatch(action函数),action<font color=’red’>可以是一个函数</font>- 该函数会被调用, 并且会传给这个函数两个参数: 一个
dispatch函数和getState函数dispatch函数用于我们之后再次派发actiongetState函数考虑到我们之后的一些操作需要依赖原来的状态,用于让我们可以获取之前的一些状态
- 默认情况下的
redux-thunk的使用
- 安装
redux-thunkyarn add redux-thunk
- 在创建
store时传入应用了middleware的enhance函数- 通过
applyMiddleware来结合多个Middleware, 返回一个enhancer - 将
enhancer作为第二个参数传入到createStore中
- 通过
- 定义返回一个函数的
action- 注意:这里不是返回一个对象了,而是一个函数
- 该函数在
dispatch之后会被执行


<details>
<summary>查看代码</summary>
<pre>import { createStore, applyMiddleware } from 'redux'</pre></details>
import reducer from './reducer'
import thunk from 'redux-thunk'<br/>
const store = createStore(
reducer,
applyMiddleware(thunk) // applyMiddleware可以使用中间件模块
)
export default store
redux-devtools
redux-devtools插件
- 我们之前讲过,
redux可以方便的让我们对状态进行跟踪和调试,那么如何做到呢?redux官网为我们提供了redux-devtools的工具- 利用这个工具,我们可以知道每次状态是如何被修改的,修改前后的状态变化等等
- 使用步骤:
- 第一步:在浏览器上安装redux-devtools扩展插件
- 第二步:在
redux中集成devtools的中间件
// store.js 开启redux-devtools扩展
import { createStore, applyMiddleware, compose } from 'redux'
// composeEnhancers函数
const composeEnhancers =
window.__REDUX_DEVTOOLS_EXTENSION_COMPOSE__({ trace: true }) || compose
// 通过applyMiddleware来结合多个Middleware,返回一个enhancer
const enhancer = applyMiddleware(thankMiddleware)
// 通过enhancer作为第二个参数传递createStore中
const store = createStore(reducer, composeEnhancers(enhancer))
export default storeredux-sage
generator
Generator函数是 ES6 提供的一种异步编程解决方案,语法行为与传统函数完全不同
Generator函数有多种理解角度。语法上,首先可以把它理解成,Generator函数是一个状态机,封装了多个内部状态。
// 生成器函数的定义
// 默认返回: Generator
function* foo() {
console.log('111')
yield 'hello'
console.log('222')
yield 'world'
console.log('333')
yield 'jane'
console.log('444')
}
// iterator: 迭代器
const result = foo()
console.log(result)
// 使用迭代器
// 调用next,就会消耗一次迭代器
const res1 = result.next()
console.log(res1) // {value: "hello", done: false}
const res2 = result.next()
console.log(res2) // {value: "world", done: false}
const res3 = result.next()
console.log(res3) // {value: "jane", done: false}
const res4 = result.next()
console.log(res4) // {value: undefined, done: true}redux-sage流程

redux-saga的使用
redux-saga是另一个比较常用在redux发送异步请求的中间件,它的使用更加的灵活Redux-saga的使用步骤如下- 安装
redux-sage:yarn add redux-saga - 集成
redux-saga中间件- 引入
createSagaMiddleware后, 需要创建一个sagaMiddleware - 然后通过
applyMiddleware使用这个中间件,接着创建saga.js这个文件 - 启动中间件的监听过程, 并且传入要监听的
saga
- 引入
saga.js文件的编写takeEvery:可以传入多个监听的actionType,每一个都可以被执行(对应有一个takeLatest,会取消前面的)put:在saga中派发action不再是通过dispatch, 而是通过putall:可以在yield的时候put多个action
- 安装
// store.js
import createSageMiddleware from 'redux-saga'
import saga from './saga'
// 1.创建sageMiddleware中间件
const sagaMiddleware = createSageMiddleware()
// 2.应用一些中间件
const enhancer = applyMiddleware(sagaMiddleware)
const store = createStore(reducer,composeEnhancers(enhancer))
sagaMiddleware.run(saga)
export default store
// saga.js
import { takeEvery, put, all } from 'redux-saga/effects'
import { FETCH_HOME_DATA } from './constant'
function* fetchHomeData(action) {
const res = yield axios.get('http://123.207.32.32:8000/home/multidata')
const banners = res.data.data.banner.list
const recommends = res.data.data.recommend.list
// dispatch action 提交action,redux-sage提供了put
yield all([
yield put(changeBannersAction(banners)),
yield put(changeRecommendAction(recommends)),
])
}
function* mySaga() {
// 参数一:要拦截的actionType
// 参数二:生成器函数
yield all([
takeEvery(FETCH_HOME_DATA, fetchHomeData),
])
}
export default mySagareducer代码拆分
Reducer代码拆分
- 我们来看一下目前我们的
reducer:- 当前这个
reducer既有处理counter的代码,又有处理home页面的数据 - 后续
counter相关的状态或home相关的状态会进一步变得更加复杂 - 我们也会继续添加其他的相关状态,比如购物车、分类、歌单等等
- 如果将所有的状态都放到一个
reducer中进行管理,随着项目的日趋庞大,必然会造成代码臃肿、难以维护
- 当前这个
- 因此,我们可以对
reducer进行拆分:- 我们先抽取一个对
counter处理的reducer - 再抽取一个对
home处理的reducer - 将它们合并起来
- 我们先抽取一个对
Reducer文件拆分
- 目前我们已经将不同的状态处理拆分到不同的
reducer中,我们来思考:- 虽然已经放到不同的函数了,但是这些函数的处理依然是在同一个文件中,代码非常的混乱
- 另外关于
reducer中用到的constant、action等我们也依然是在同一个文件中;

combineReducers函数
- 目前我们合并的方式是通过每次调用
reducer函数自己来返回一个新的对象 - 事实上,
redux给我们提供了一个combineReducers函数可以方便的让我们对多个reducer进行合并
import { combineReducers } from 'redux'
import { reducer as counterReducer } from './count'
import { reducer as homeReducer } from './home'
export const reducer = combineReducers({
counterInfo: counterReducer,
homeInfo: homeReducer,
})- 那么
combineReducers是如何实现的呢?- 它将我们传递的
reducer合并成一个对象, 最终返回一个combination函数 - 在执行
combination函数过程中, 会通过判断前后返回的数据是否相同来决定返回之前的state还是新的state
- 它将我们传递的
immutableJs
数据可变形的问题
- 在
React开发中,我们总是会强调数据的不可变性:- 无论是类组件中的
state,还是reduex中管理的state - 事实上在整个
JavaScript编码的过程中,数据的不可变性都是非常重要的
- 无论是类组件中的
- 数据的可变性引发的问题(案例):
- 我们明明没有修改obj,只是修改了obj2,但是最终obj也被我们修改掉了
- 原因非常简单,对象是引用类型,它们指向同一块内存空间,两个引用都可以任意修改
const obj1 = { name: 'jane', age: 18 }
const obj2 = obj1
obj1.name = 'kobe'
console.log(obj2.name) // kobe- 有没有办法解决上面的问题呢?
- 进行对象的拷贝即可:
Object.assign或扩展运算符
- 进行对象的拷贝即可:
- 这种对象的浅拷贝有没有问题呢?
- 从代码的角度来说,没有问题,也解决了我们实际开发中一些潜在风险
- 从性能的角度来说,有问题,如果对象过于庞大,这种拷贝的方式会带来性能问题以及内存浪费
- 有人会说,开发中不都是这样做的吗?
- 从来如此,便是对的吗?
认识ImmutableJS
- 为了解决上面的问题,出现了
Immutable对象的概念:Immutable对象的特点是只要修改了对象,就会返回一个新的对象,旧的对象不会发生改变;
- 但是这样的方式就不会浪费内存了吗?
- 为了节约内存,又出现了一个新的算法:
Persistent Data Structure(持久化数据结构或一致性数据结构)
- 为了节约内存,又出现了一个新的算法:
- 当然,我们一听到持久化第一反应应该是数据被保存到本地或者数据库,但是这里并不是这个含义:
- 用一种数据结构来保存数据
- 当数据被修改时,会返回一个对象,但是新的对象会尽可能的利用之前的数据结构而不会对内存造成浪费,如何做到这一点呢?结构共享:

- 安装
Immutable:yarn add immutable
ImmutableJS常见API
注意:我这里只是演示了一些API,更多的方式可以参考官网
作用:不会修改原有数据结构,返回一个修改后新的拷贝对象
JavaScrip和ImutableJS直接的转换- 对象转换成
Immutable对象:Map - 数组转换成
Immtable数组:List - 深层转换:
fromJS
- 对象转换成
const im = Immutable
// 对象转换成Immutable对象
const info = {name: 'kobe', age: 18}
const infoIM = im.Map()
// 数组转换成Immtable数组
const names = ["abc", "cba", "nba"]
const namesIM = im.List(names)ImmutableJS的基本操作:- 修改数据:
set(property, newVal)- 返回值: 修改后新的数据结构
- 获取数据:
get(property/index) - 获取深层
Immutable对象数据(子属性也是Immutable对象):getIn(['recommend', 'topBanners'])
- 修改数据:
// set方法 不会修改infoIM原有数据结构,返回修改后新的数据结构
const newInfo2IM = infoIM.set('name', 'james')
const newNamesIM = namesIM.set(0, 'why')
// get方法
console.log(infoIM.get('name'))// -> kobe
console.log(namesIM.get(0))// -> abc结合Redux管理数据
ImmutableJS重构redux- yarn add Immutable
- yarn add redux-immutable
- 使用redux-immutable中的combineReducers;
- 所有的reducer中的数据都转换成Immutable类型的数据
FAQ
React中的state如何管理
- 目前项目中采用的state管理方案(参考即可):
- 相关的组件内部可以维护的状态,在组件内部自己来维护
- 只要是需要共享的状态,都交给redux来管理和维护
- 从服务器请求的数据(包括请求的操作) ,交给redux来维护
前言
hello大家好,我是风不识途,最近一直在整理
redux系列文章,发现对于初学者不太友好,关系错综复杂,难倒是不太难,就是比较复杂redux、react-redux、redux-thunk还有redux-sage,immutable(多图预警),由于知识点比较多,建议先收藏(收藏等于学会了
认识纯函数
JavaScript纯函数
- 函数式编程中有一个概念叫纯函数,
JavaScript符合函数式编程的范式, 所以也有纯函数的概念 - 在
React中,纯函数的概念非常重要,在接下来我们学习的Redux中也非常重要,所以我们必须来回顾一下纯函数 -
纯函数的维基百科定义(了解即可) - 纯函数的定义简单总结一下:
* 纯函数指的是, 每次给相同的参数, 一定返回相同的结果 * 函数在执行过程中, 不能产生副作用 -
**纯函数( `Pure Function` )的注意事项:**
React中的纯函数
- 为什么纯函数在函数式编程中非常重要呢?
* 因为你可以安心的写和安心的用 * 你在写的时候保证了函数的纯度,实现自己的业务逻辑即可,不需要关心传入的内容或者函数体依赖了外部的变量 * 你在用的时候,你确定你的输入内容不会被任意篡改,并且自己确定的输入,一定会有确定的输出 - React非常灵活,但它也有一个严格的规则:
* 所有React组件都必须像"纯函数"一样保护它们的"props"不被更改
认识Redux
为什么需要redux
JavaScript开发的应用程序, 已经变得非常复杂了:* `JavaScript`**需要管理的状态越来越多**, 越来越复杂了 * 这些状态包括服务器返回的数据, 用户操作的数据等等, 也包括一些`UI`的状态- 管理不断变化的
state是非常困难的:* **状态之间相互存在依赖**, 一个状态的变化会引起另一个状态的变化, `View`页面也有可能会引起状态的变化 * 当程序复杂时, `state`在什么时候, 因为什么原因发生了变化, 发生了怎样的变化, 会变得非常难以控制和追踪
React的作用
React只是在视图层帮助我们解决了DOM的渲染过程, 但是state依然是留给我们自己来管理:* 无论是组件定义自己的`state`,还是组件之间的通信通过`props`进行传递 * 也包括通过`Context`进行数据之间的共享 * `React`主要负责帮助我们管理视图,`state`如何维护最终还是我们自己来决定

Redux就是一个帮助我们管理State的容器:* `Redux`是`JavaScript`的状态容器, 提供了可预测的状态管理Redux除了和React一起使用之外, 它也可以和其他界面库一起来使用(比如Vue), 并且它非常小 (包括依赖在内,只有2kb)
Redux的核心理念-Store
Redux的核心理念非常简单- 比如我们有一个朋友列表需要管理:
* **如果我们没有定义统一的规范来操作这段数据,那么整个数据的变化就是无法跟踪的** * 比如页面的某处通过`products.push`的方式增加了一条数据 * 比如另一个页面通过`products[0].age = 25`修改了一条数据 - 整个应用程序错综复杂,当出现
bug时,很难跟踪到底哪里发生的变化
Redux的核心理念-action
Redux要求我们通过action来更新state:* **所有数据的变化, 必须通过**`dispatch`来派发`action`来更新 * `action`是一个普通的`JavaScript`对象,用来描述这次更新的`type`和`content`- 比如下面就是几个更新
friends的action:* 强制使用`action`的好处是可以清晰的知道数据到底发生了什么样的变化,所有的数据变化都是可跟追踪、可预测的 * 当然,目前我们的`action`是固定的对象,真实应用中,我们会通过函数来定义,返回一个`action`
Redux的核心理念-reducer
- 但是如何将
state和action联系在一起呢? 答案就是reducer* `reducer`是一个纯函数 * `reducer`做的事情就是将传入的`state`和`action`结合起来来生成一个新的`state`
Redux的三大原则
- 单一数据源
* 整个应用程序的`state`被存储在一颗`object tree`中, 并且这个`object tree`只存储在一个`store` * `Redux`并没有强制让我们不能创建多个`Store`,但是那样做并不利于数据的维护 * 单一的数据源可以让整个应用程序的`state`变得方便维护、追踪、修改 - State是只读的
* 唯一修改`state`的方法一定是触发`action`, 不要试图在其它的地方通过任何的方式来修改`state` * 这样就确保了`View`或网络请求都不能直接修改`state`,它们只能通过`action`来描述自己想要如何修改`state` * 这样可以保证所有的修改都被集中化处理,并且按照严格的顺序来执行,所以不需要担心`race condition`(竟态)的问题 - 使用纯函数来执行修改
* 通过`reducer`将旧 `state` 和 `action` 联系在一起, 并且返回一个新的`state` * 随着应用程序的复杂度增加,我们可以将`reducer`拆分成多个小的`reducers`,分别操作不同`state tree`的一部分 * 但是所有的`reducer`都应该是纯函数,不能产生任何的副作用
Redux的基本使用
Redux中核心的API
redux的安装: yarn add redux
createStore可以用来创建store对象store.dispatch用来派发action,action会传递给storereducer接收action,reducer计算出新的状态并返回它 (store负责调用reducer)store.getState这个方法可以帮助获取store里边所有的数据内容store.subscribe方法可以让让我们订阅store的改变,只要store发生改变,store.subscribe这个函数接收的这个回调函数就会被执行
小结
- 创建
sotore, 决定 store 要保存什么状态 - 创建
action, 用户在程序中实现什么操作 - 创建
reducer, reducer 接收 action 并返回更新的状态
Redux的使用过程
- 创建一个对象, 作为我们要保存的状态
- 创建
Store来存储这个state* 创建`store`时必须创建`reducer` * 我们可以通过 `store.getState` 来获取当前的`state` - 通过
action来修改state* 通过`dispatch`来派发`action` * 通常`action`中都会有`type`属性,也可以携带其他的数据 - 修改
reducer中的处理代码* 这里一定要记住,`reducer`是一个**纯函数**,不能直接修改`state` * 后面会讲到直接修改`state`带来的问题 - 可以在派发
action之前,监听store的变化
import { createStore } from ‘redux’
// 1.初始化state
const initState = { counter: 0 }
// 2.reducer纯函数 不能修改传递的state
function reducer(state = initState, action) {
switch (action.type) {
case ‘INCREMENT’:
return { …state, counter: state.counter + 1 }
case ‘ADD_COUNTER’:
return { …state, counter: state.counter + action.num }
default:
return state
}
}
// 3.store 参数放一个reducer
const store = createStore(reducer)
// 4.action
const action1 = { type: ‘INCREMENT’ }
const action2 = { type: ‘ADD_COUNTER’, num: 2 }
// 5.订阅store的修改
store.subscribe(() => {
console.log(‘state发生了改变: ‘, store.getState().counter)
})
// 6.派发action
store.dispatch(action1)
store.dispatch(action2)
Redux结构划分
- 如果我们将所有的逻辑代码写到一起, 那么当
redux变得复杂时代码就难以维护 - 对代码进行拆分, 将
store、reducer、action、constants拆分成一个个文件
拆分目录
Redux使用流程
Redux官方流程图
React-Redux的使用
redux融入react代码(案例)
redux融入react代码案例:* `Home`组件:其中会展示当前的`counter`值,并且有一个+1和+5的按钮 * `Profile`组件:其中会展示当前的`counter`值,并且有一个-1和-5的按钮
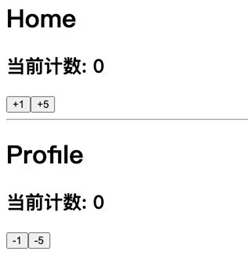
- 核心代码主要是两个:
* 在 `componentDidMount`中订阅数据的变化,当数据发生变化时重新设置 `counter` * 在发生点击事件时,调用`store`的`dispatch`来派发对应的`action`
自定义connect函数
当我们多个组件使用
redux时, 重复的代码太多了, 比如: 订阅state取消订阅state或 派发action获取state将重复的代码进行封装, 将不同的
state和dispatch作为参数进行传递
// connect.js
import React, { PureComponent } from ‘react’
import { StoreContext } from ‘./context’
/**
- 1.调用该函数: 返回一个高阶组件
- 传递需要依赖 state 和 dispatch 来使用state或通过dispatch来改变state
* - 2.调用高阶组件:
- 传递该组件需要依赖 store 的组件
* - 3.主要作用:
- 将重复的代码抽取到高阶组件中,并将该组件依赖的 state 和 dispatch
- 通过调用mapStateToProps()或mapDispatchToProps()函数
- 并将该组件依赖的state和dispatch供该组件使用,其他使用store的组件不必依赖store
* - 4.connect.js: 优化依赖
- 目的:但是上面的connect函数有一个很大的缺陷:依赖导入的 store
- 优化:正确的做法是我们提供一个Provider,Provider来自于我们
- Context,让用户将store传入到value中即可;
*/
export function connect(mapStateToProps, mapDispatchToProps) {
return function enhanceComponent(WrapperComponent) {
class EnhanceComponent extends PureComponent {
constructor(props, context) {
super(props, context)
// 组件依赖的state
this.state = {
storeState: mapStateToProps(context.getState()),
}
}
// 订阅数据发生变化,调用setState重新render
componentDidMount() {
this.unsubscribe = this.context.subscribe(() => {
this.setState({
centerStore: mapStateToProps(this.context.getState()),
})
})
}
// 组件被卸载取消订阅
componentWillUnmount() {
this.unsubscribe()
}
render() {
// 下面的WrapperComponent相当于 home 组件(就是你传递的组件)
// 你需要将该组件需要依赖的state和dispatch作为props进行传递
return (
<WrapperComponent
{…this.props}
{…mapStateToProps(this.context.getState())}
{…mapDispatchToProps(this.context.dispatch)}
/>
)
}
}
// 取出Provider提供的value
EnhanceComponent.contextType = StoreContext
return EnhanceComponent
}
}
// home.js
// 定义组件依赖的state和dispatch
const mapStateToProps = state => ({
counter: state.counter,
})
const mapDispatchToProps = dispatch => ({
increment() {
dispatch(increment())
},
addNumber(num) {
dispatch(addAction(num))
},
})
export default connect(mapStateToProps,mapDispatchToProps)(依赖redux的组件)
react-redux使用
- 开始之前需要强调一下,
redux和react没有直接的关系,你完全可以在React, Angular, Ember, jQuery, or vanilla JavaScript中使用Redux - 尽管这样说,redux依然是和React或者Deku的库结合的更好,因为他们是通过state函数来描述界面的状态,Redux可以发射状态的更新,让他们作出相应。
- 虽然我们之前已经实现了
connect、Provider这些帮助我们完成连接redux、react的辅助工具,但是实际上redux官方帮助我们提供了react-redux的库,可以直接在项目中使用,并且实现的逻辑会更加的严谨和高效 - 安装
react-redux:* `yarn add react-redux`
// 1.index.js
import { Provider } from ‘react-redux’
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById(‘root’)
)
// 2.home.js
import { connect } from ‘react-redux’
// 定义需要依赖的state和dispatch (函数需要返回一个对象)
export default connect(mapStateToProps, mapDispatchToProps)(About)
react-redux源码导读
Redux-Middleware中间件
组件中异步操作
- 在之前简单的案例中,
redux中保存的counter是一个本地定义的数据* 我们可以直接通过同步的操作来`dispatch action`,`state`就会被立即更新。 * 但是真实开发中,`redux`中保存的**很多数据可能来自服务器**,我们需要进行**异步的请求**,再将数据保存到`redux`中 - 网络请求可以在
class组件的componentDidMount中发送,所以我们可以有这样的结构:
redux中异步操作
- 上面的代码有一个缺陷:
* 我们必须将**网络请求**的异步代码放到组件的生命周期中来完成 - 为什么将网络请求的异步代码放在
redux中进行管理?* 后期代码量的增加,如果把网络请求异步函数放在组件的生命周期里,这个生命周期函数会变得越来越复杂,组件就会变得越来越大 * 事实上,**网络请求到的数据也属于状态管理的一部分**,更好的一种方式应该是将其也交给`redux`来管理
- 但是在
redux中如何可以进行异步的操作呢?* **使用中间件 (Middleware)** * 学习过`Express`或`Koa`框架的童鞋对中间件的概念一定不陌生 * 在这类框架中,`Middleware`可以帮助我们在**请求和响应之间嵌入一些操作的代码**,比如cookie解析、日志记录、文件压缩等操作
理解中间件(重点)
redux也引入了中间件 (Middleware) 的概念:* 这个中间件的目的是在`dispatch`的`action`和最终达到的`reducer`之间,扩展一些自己的代码 * 比如日志记录、**调用异步接口**、添加代码调试功能等等
redux-thunk是如何做到让我们可以发送异步的请求呢?* 默认情况下的`dispatch(action)`,`action`需要是一个`JavaScript`的对象 * `redux-thunk`可以让`dispatch`(`action`函数), `action`**可以是一个函数** * 该函数会被调用, 并且会传给这个函数两个参数: 一个`dispatch`函数和`getState`函数 * `dispatch`函数用于我们之后再次派发`action` * `getState`函数考虑到我们之后的一些操作需要依赖原来的状态,用于让我们可以获取之前的一些状态
redux-thunk的使用
- 安装
redux-thunk* `yarn add redux-thunk` - 在创建
store时传入应用了middleware的enhance函数* 通过`applyMiddleware`来结合多个`Middleware`, 返回一个`enhancer` * 将`enhancer`作为第二个参数传入到`createStore`中  - 定义返回一个函数的
action* 注意:这里不是返回一个对象了,而是一个**函数** * 该函数在`dispatch`之后会被执行
查看代码
redux-devtools
redux-devtools插件
- 我们之前讲过,
redux可以方便的让我们对状态进行跟踪和调试,那么如何做到呢?* `redux`官网为我们提供了`redux-devtools`的工具 * 利用这个工具,我们可以知道每次状态是如何被修改的,修改前后的状态变化等等 - 使用步骤:
* 第一步:在浏览器上安装[redux-devtools](https://chrome.google.com/webstore/detail/redux-devtools/lmhkpmbekcpmknklioeibfkpmmfibljd/related?utm_source=chrome-ntp-icon)扩展插件 * 第二步:在`redux`中集成`devtools`的中间件
// store.js 开启redux-devtools扩展
import { createStore, applyMiddleware, compose } from ‘redux’
// composeEnhancers函数
const composeEnhancers =
window.__REDUX_DEVTOOLS_EXTENSION_COMPOSE__({ trace: true }) || compose
// 通过applyMiddleware来结合多个Middleware,返回一个enhancer
const enhancer = applyMiddleware(thankMiddleware)
// 通过enhancer作为第二个参数传递createStore中
const store = createStore(reducer, composeEnhancers(enhancer))
export default store
redux-sage
generator
Generator函数是 ES6 提供的一种异步编程解决方案,语法行为与传统函数完全不同
Generator函数有多种理解角度。语法上,首先可以把它理解成,Generator函数是一个状态机,封装了多个内部状态。
// 生成器函数的定义
// 默认返回: Generator
function* foo() {
console.log(‘111’)
yield ‘hello’
console.log(‘222’)
yield ‘world’
console.log(‘333’)
yield ‘jane’
console.log(‘444’)
}
// iterator: 迭代器
const result = foo()
console.log(result)
// 使用迭代器
// 调用next,就会消耗一次迭代器
const res1 = result.next()
console.log(res1) // {value: “hello”, done: false}
const res2 = result.next()
console.log(res2) // {value: “world”, done: false}
const res3 = result.next()
console.log(res3) // {value: “jane”, done: false}
const res4 = result.next()
console.log(res4) // {value: undefined, done: true}
redux-sage流程
redux-saga的使用
redux-saga是另一个比较常用在redux发送异步请求的中间件,它的使用更加的灵活Redux-saga的使用步骤如下1. 安装`redux-sage`: `yarn add redux-saga` 2. 集成`redux-saga`中间件 * 引入 `createSagaMiddleware` 后, 需要创建一个 `sagaMiddleware` * 然后通过 `applyMiddleware` 使用这个中间件,接着创建 `saga.js` 这个文件 * 启动中间件的监听过程, 并且传入要监听的`saga` 3. `saga.js`文件的编写 * `takeEvery`:可以传入多个监听的`actionType`,每一个都可以被执行(对应有一个`takeLatest`,会取消前面的) * `put`:在`saga`中派发`action`不再是通过`dispatch`, 而是通过`put` * `all`:可以在`yield`的时候`put`多个`action`
// store.js
import createSageMiddleware from ‘redux-saga’
import saga from ‘./saga’
// 1.创建sageMiddleware中间件
const sagaMiddleware = createSageMiddleware()
// 2.应用一些中间件
const enhancer = applyMiddleware(sagaMiddleware)
const store = createStore(reducer,composeEnhancers(enhancer))
sagaMiddleware.run(saga)
export default store
// saga.js
import { takeEvery, put, all } from ‘redux-saga/effects’
import { FETCH_HOME_DATA } from ‘./constant’
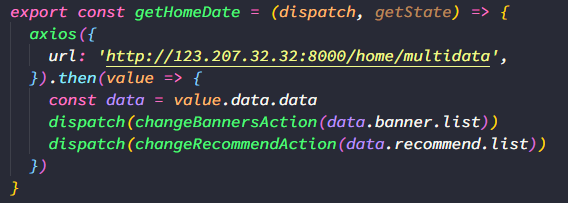
function* fetchHomeData(action) {
const res = yield axios.get(‘http://123.207.32.32:8000/hom…
const banners = res.data.data.banner.list
const recommends = res.data.data.recommend.list
// dispatch action 提交action,redux-sage提供了put
yield all([
yield put(changeBannersAction(banners)),
yield put(changeRecommendAction(recommends)),
])
}
function* mySaga() {
// 参数一:要拦截的actionType
// 参数二:生成器函数
yield all([
takeEvery(FETCH_HOME_DATA, fetchHomeData),
])
}
export default mySaga
reducer代码拆分
Reducer代码拆分
- 我们来看一下目前我们的
reducer:* 当前这个`reducer`既有处理`counter`的代码,又有处理`home`页面的数据 * 后续`counter`相关的状态或`home`相关的状态会进一步变得更加复杂 * 我们也会继续添加其他的相关状态,比如购物车、分类、歌单等等 * 如果将所有的状态都放到一个`reducer`中进行管理,随着项目的日趋庞大,必然会造成代码臃肿、难以维护 - 因此,我们可以对
reducer进行拆分:* 我们先抽取一个对`counter`处理的`reducer` * 再抽取一个对`home`处理的`reducer` * 将它们合并起来
Reducer文件拆分
- 目前我们已经将不同的状态处理拆分到不同的
reducer中,我们来思考:* 虽然已经放到不同的函数了,但是这些函数的处理依然是在同一个文件中,代码非常的混乱 * 另外关于`reducer`中用到的`constant`、`action`等我们也依然是在同一个文件中;
combineReducers函数
- 目前我们合并的方式是通过每次调用
reducer函数自己来返回一个新的对象 - 事实上,
redux给我们提供了一个combineReducers函数可以方便的让我们对多个reducer进行合并
import { combineReducers } from ‘redux’
import { reducer as counterReducer } from ‘./count’
import { reducer as homeReducer } from ‘./home’
export const reducer = combineReducers({
counterInfo: counterReducer,
homeInfo: homeReducer,
})
- 那么
combineReducers是如何实现的呢?* 它将我们传递的`reducer`合并成一个对象, 最终返回一个`combination`函数 * 在执行`combination`函数过程中, 会通过判断前后返回的数据是否相同来决定返回之前的`state`还是新的`state`
immutableJs
数据可变形的问题
- 在
React开发中,我们总是会强调数据的不可变性:* 无论是类组件中的`state`,还是`reduex`中管理的`state` * 事实上在整个`JavaScript`编码的过程中,数据的不可变性都是非常重要的 - 数据的可变性引发的问题(案例):
* 我们明明没有修改obj,只是修改了obj2,但是最终obj也被我们修改掉了 * 原因非常简单,对象是引用类型,它们指向同一块内存空间,两个引用都可以任意修改
const obj1 = { name: ‘jane’, age: 18 }
const obj2 = obj1
obj1.name = ‘kobe’
console.log(obj2.name) // kobe
- 有没有办法解决上面的问题呢?
* 进行对象的拷贝即可:`Object.assign`或扩展运算符 - 这种对象的浅拷贝有没有问题呢?
* 从代码的角度来说,没有问题,也解决了我们实际开发中一些潜在风险 * 从性能的角度来说,有问题,如果对象过于庞大,这种拷贝的方式会带来性能问题以及内存浪费 - 有人会说,开发中不都是这样做的吗?
* 从来如此,便是对的吗?
认识ImmutableJS
- 为了解决上面的问题,出现了
Immutable对象的概念:* `Immutable`对象的特点是只要修改了对象,就会返回一个新的对象,旧的对象不会发生改变; - 但是这样的方式就不会浪费内存了吗?
* 为了节约内存,又出现了一个新的算法:`Persistent Data Structure`(持久化数据结构或一致性数据结构) - 当然,我们一听到持久化第一反应应该是数据被保存到本地或者数据库,但是这里并不是这个含义:
* 用一种数据结构来保存数据 * 当数据被修改时,会返回一个对象,但是**新的对象会尽可能的利用之前的数据结构而不会对内存造成浪费**,如何做到这一点呢?结构共享:
- 安装
Immutable:yarn add immutable
ImmutableJS常见API
注意:我这里只是演示了一些API,更多的方式可以参考官网
作用:不会修改原有数据结构,返回一个修改后新的拷贝对象
JavaScrip和ImutableJS直接的转换* 对象转换成`Immutable`对象:`Map` * 数组转换成`Immtable`数组:`List` * 深层转换:`fromJS`
const im = Immutable
// 对象转换成Immutable对象
const info = {name: ‘kobe’, age: 18}
const infoIM = im.Map()
// 数组转换成Immtable数组
const names = [“abc”, “cba”, “nba”]
const namesIM = im.List(names)
ImmutableJS的基本操作:* 修改数据:`set(property, newVal)` * 返回值: 修改后新的数据结构 * 获取数据:`get(property/index)` * 获取深层`Immutable`对象数据(子属性也是`Immutable`对象): `getIn(['recommend', 'topBanners'])`
// set方法 不会修改infoIM原有数据结构,返回修改后新的数据结构
const newInfo2IM = infoIM.set(‘name’, ‘james’)
const newNamesIM = namesIM.set(0, ‘why’)
// get方法
console.log(infoIM.get(‘name’))// -> kobe
console.log(namesIM.get(0))// -> abc
结合Redux管理数据
ImmutableJS重构redux* yarn add Immutable * yarn add redux-immutable- 使用redux-immutable中的combineReducers;
- 所有的reducer中的数据都转换成Immutable类型的数据
FAQ
React中的state如何管理
- 目前项目中采用的state管理方案(参考即可):
* 相关的组件内部可以维护的状态,在组件内部自己来维护 * 只要是需要共享的状态,都交给redux来管理和维护 * 从服务器请求的数据(包括请求的操作) ,交给redux来维护